Exploring Azure's Data Lake


Recently Microsoft revealed their plans for Azure Data Lake and how it groups several big data services in Azure under one umbrella.
In this blog post I'll walk you through what it offers and how it enable you to re-use your existing skills to analyse big data.
What is Azure Data Lake?
Azure Data Lake is a family of Azure services that enable you to analyse your big data workloads in a managed manner.
It consists of three services:
- Azure Data Lake Store - A data repository that enables you to store any type of data in its raw format.
- Azure Data Lake Analytics - An analytics service that enables you to run jobs on data sets without having to think about clusters.
- Azure Data Lake HDInsight - An anlytics service that enables you to analyse data sets on a managed cluster running open-source technologies such as Hadoop, Spark, Storm & HBase. You can either run these clusters on Windows or since recently also on Linux. This is an existing services that joined the family.
Here is an overview of the big data family.
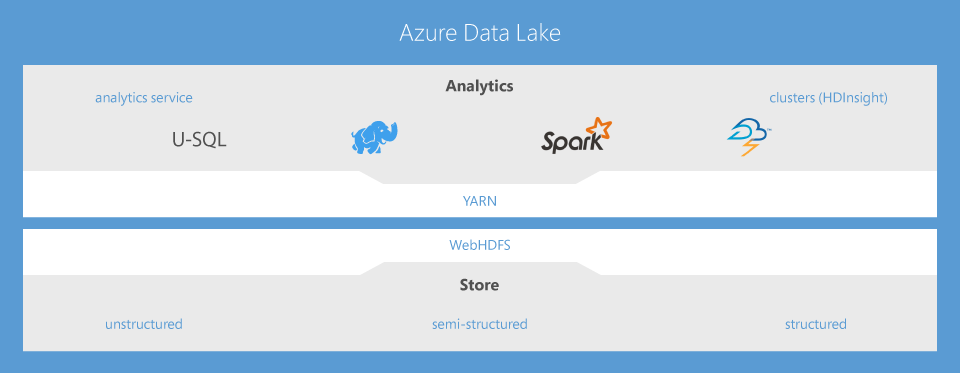
© Microsoft Azure
Azure Data Lake is built on the learnings from their internal big data service called Cosmos. It uses SCOPE as a query language and is build on top of Dryad, a Microsoft Research project.
Services such as Bing, Xbox Live, Office365 & Skype are built on top of Cosmos running more than a million jobs a day.
Let's dive a bit more in detail what Azure Data Lake Store & Analytics leverage us.
Data Lake Store - Thé storage for big data in Azure
Data Lake Store is a data repository that enables you to store all kinds of data in their raw format without defining schemas.
The store offers unlimited storage with immediate read/write access to it and scaling the throughput you need for your workloads. It's also offers small writes at low latency for big data sets.
Azure Data Store is fully integrated with Azure Active Directory allowing you to re-use your existing active directory and leveraging enterprise-grade security on top of your data.
This is the "Azure Data Lake" Microsoft originally announced at //BUILD/.
These are the typical characteristics of a Data Lake, an existing concept in the data space. Let's have a look what exactly a data lake is.
What is a Data Lake?
Martin Fowler wrote an interesting article explaining what a data lake is and how it's different from a data warehouse.
- A data warehouse enables you to store data in a structured manner and is coupled to one or more schemas. Before the data is stored in the warehouse, it sometimes needs to be cleansed and transformed in the destination schema.
- A data lake is a single repository that holds all your data in its raw format. It allows data scientists to analyse that data without losing any valuable data without knowing.
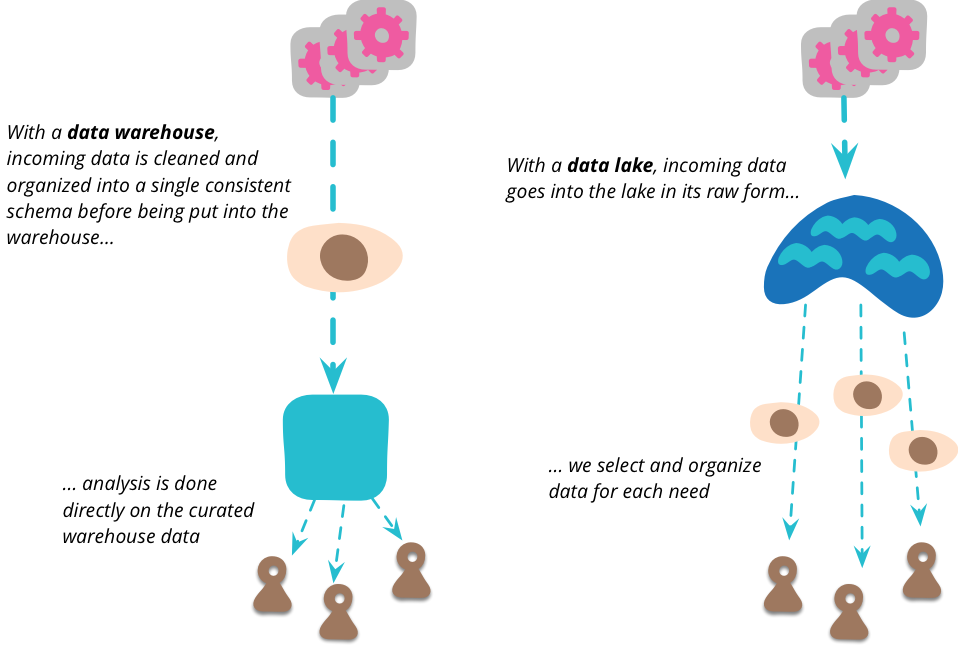
© Martin Fowler
However, both concepts have their drawbacks.
- Without decent metadata on what's in your Data Lake it might turn into a Data Swamp before you know it.
- A data warehouse is tight to the schemas which means that you're not storing data that is interesting at this moment, but could be later on...
I really recommend reading Martin his article on Data Lakes.
Re-using existing tools & technologies
The Store is WebHDFS compatible allowing to use your existing tools to manage your data or analyse the data from any processing technology.
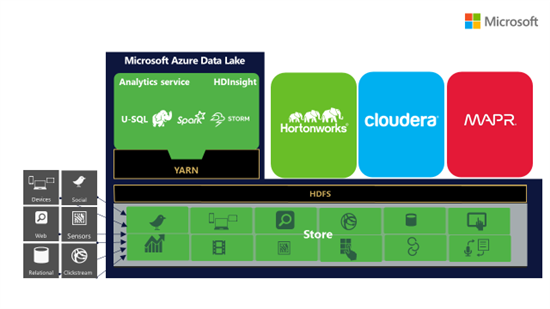
© Microsoft Azure
How about Azure Storage?
Azure now has two data services for storing blobs - Azure Storage & Azure Data Lake Store. When do I use which one?
I think it's safe to say that Azure Data Lake Store is thé data store for all your big data in Azure. If you're planning for analysing it, store it in Data Lake because of its unlimited size, low r/w latency, etc.
So when should I use Azure Storage? It's simple, all other scenarios and the data size is within the Azure Storage limits.
From a princing perspective I think we might speculate that Azure Data Lake Store will be more expensive than Azure Storage because of several features such as enterprice-grade security based on Azure AD.
However, it still depends on several other factors such as what will the data durability offering be, are there different data tiers, etc.
Analysing you data with Data Lake Analytics
Azure Data Lake Analytics allows you to run analysis jobs on data without having to worry about clusters. Azure will run your jobs on clusters that are setup & managed by them. By using Apache YARN, Analytics is able to manage its resources for its processing engine as good as possible.
By using the U-SQL query language -which we will discuss next- you can process data from several data sources such as Azure Data Lake Store, Azure Blob Storage, Azure SQL Database but also from other data stores built on HDFS. Microsoft is also planning support for other query languages -such as Hive- but no timeframe was defined.
By using more units you can easily scale the processing of your job. This means that your job will be executed over multiple vertices that will distribute the workload by splitting files into segments for example.
With Azure Data Lake Analytics you pay only for the jobs you run instead of running a clusters (that is idle). However, they didn't announce anything on the pricing.
Here is an example of Azure Data Lake Analytics looks like in the portal.
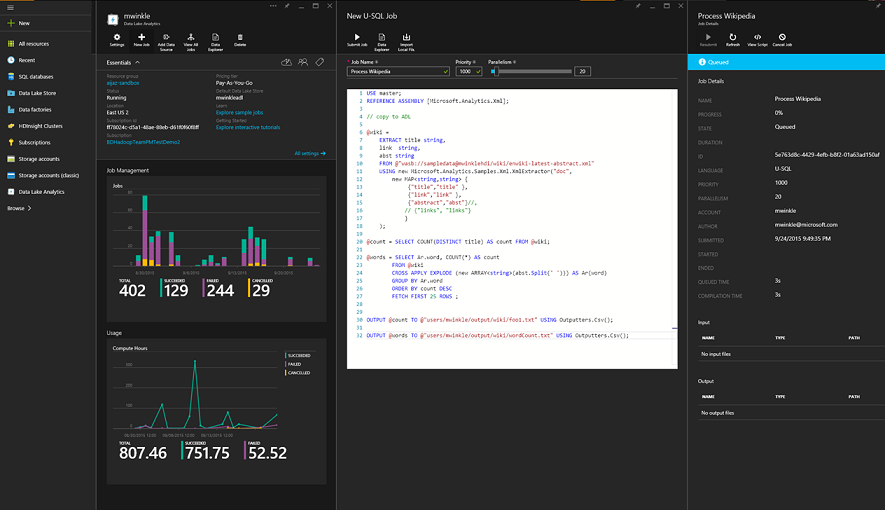
© Matt Winkler, Microsoft
SQL + C# = U-SQL
U-SQL is a new querying language designed by Microsoft that enables you to run your queries in a distributed manner. It is built on the learnings from T-SQL, ANSI-SQL & Hive and a SQL syntax with C# extensibility. Whether you're working on small files or files bigger than 1 exabytes, U-SQL can query it!
By using a Extract-Transform-Output pattern you can process your data and come with out-of-the-box extracters & outputters or you can build your own in C#!
The language also supports other interesting features such using partition tables or using variables in folder paths, these allow you to add the variable to the output data set.
Also you can run inline C# statements or call external assemblies from within your script.
Michael Rys explains you how you can use U-SQL with some examples. Here is one of them.

Azure Data Lake Tools for Visual Studio
With these new services comes new tooling called the Azure Data Lake Tools for Visual Studio. These tools allow you to be more productive with U-SQL, Azure Data Lake Store & Analytics from within Visual Studio.
One of the features allows you to preview a file in the Store. You can then select the delimiter, qualifier & encoding in order to get a live preview. It's also possible to save that file locally or preview it in Excel.
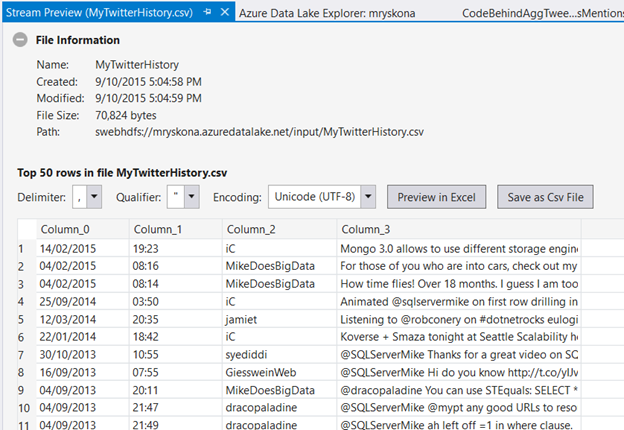
© Michael Rys, Microsoft
Another feature allows you to trigger, visualize, debug & playback Analytics jobs. This allows you to see how much data is read/written, pin-point performance issues or just see the current status of your job.
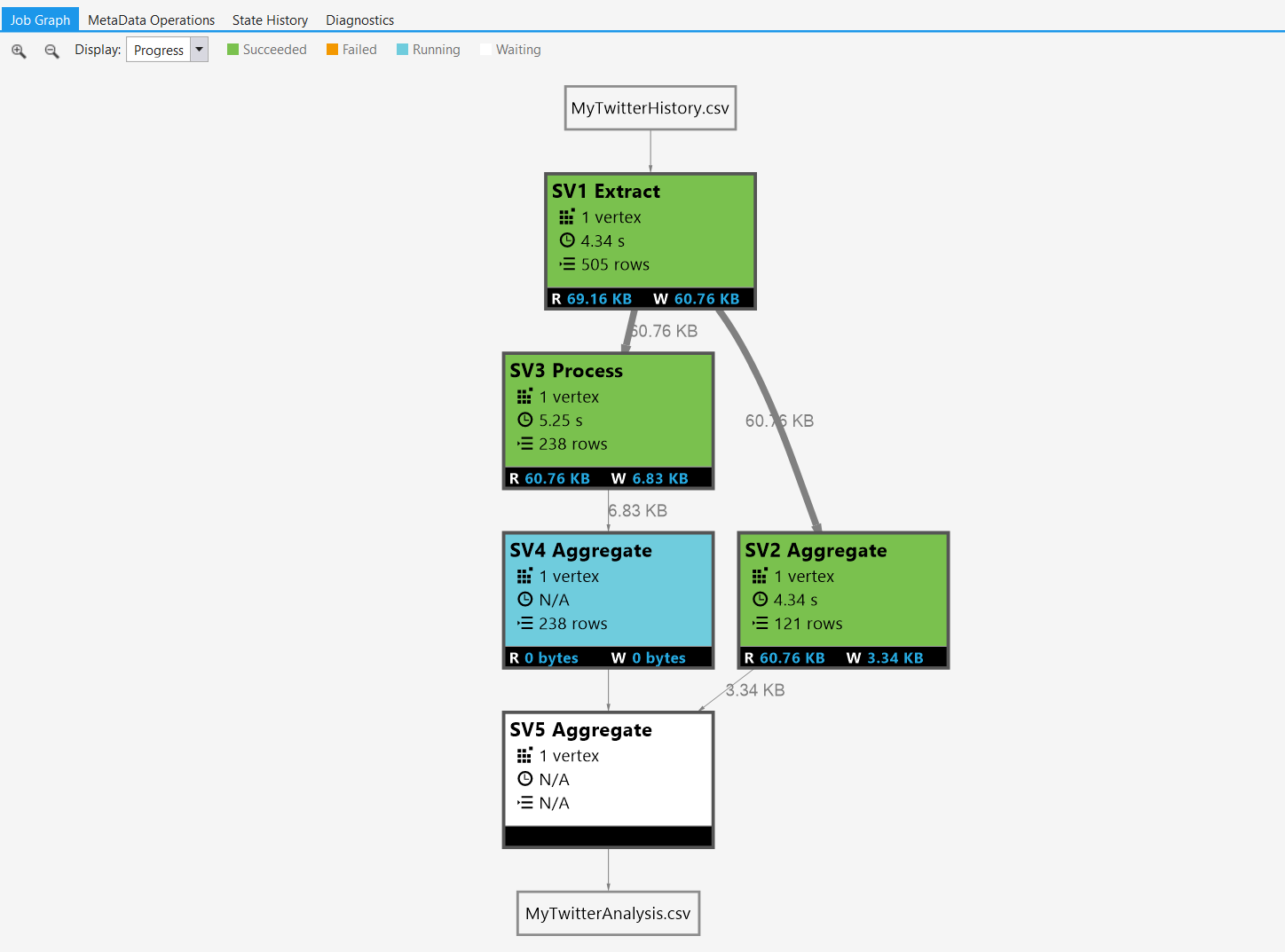
© Michael Rys, Microsoft
One other interesting thing is that you can create & build your U-SQL scripts in Visual Studio. This allows you to verify your syntax before running your jobs and enables you to add them to your source control and collaborate on them.
In general, this tooling allows you to be productive with Azure Data Lake without the need to leave your (precious) IDE! I can personally say that these tools are really great and a nice addition to Visual Studio!
This video walks you through some of the features available.
Integrating Azure Data Lake in your data pipelines
Gaurav Malhotra announced that Azure Data Factory will offer a source & sink for Azure Data Lake Store.
This will allow you to move data to Azure Data Lake Store or export it to another data store in Azure or on-premises, i.e. Azure Blob Storage or on-premises file system.
Unfortunately, there is no news on Azure Data Lake Analytics integration (yet). It sounds feasible to be able to trigger jobs from within you data pipelines.
Openness at Microsoft
We've all noticed that things at Microsoft have changed with the coming of Satya on all fronts, also on the openness of the company.
In the past few years Microsoft has been contributing to several open-source technologies such as Docker and have open-sourced some of their own technologies in the .NET foundation.

In order to the announcements made around Azure Data Lake, Microsoft has been working closely with partners such as Hortonworks to make their platform compatbile with existing open-source technologies. They have also contributed to several projects going from YARN & Hive to WebHDFS and beyond.
![]()
T. K. “Ranga” Rengarajan announced that it has been working closely with partners to ensure you have the best applications available to work with Azure Data Lake. Some of these partners are BlueTalon & Dataguise for big data security & governance or Datameer for end-to-end big data analytics.
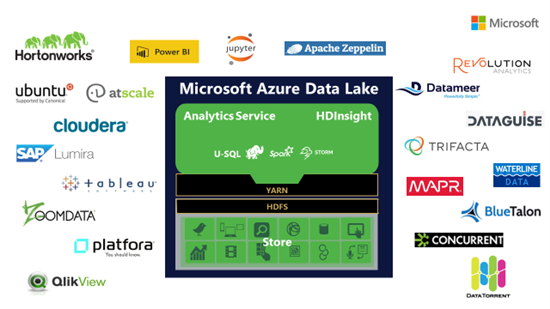
Intersted in more? Raghu walks you through some of the contributions that were made by Microsoft.
Azure Data Lake Opens A New World For Developers
The Azure Data Lake services offer data scientist & developers an easy-to-use platform for storing & analysing big data by using clusters (HDInsight) or using jobs (Analytics). With the addition of HDInsight to the family, Azure Data Lake is your answer for Big Data in Azure.
People whom have experience with big data can choose to run their jobs on a managed cluster -Running Hadoop, Spark or another technology- or let Analytics run it in the future.
On the other hand, Analytics allow developers to re-use their existing skills. That's what exactly what Codit did.
U-SQL was especially helpful because we were able to get up and running using our existing skills with .NET and SQL. This made big data easy because we didn’t have to learn a whole new paradigm.
With Azure Data Lake, we were able to process data coming in from smart meters and combine it with the energy spot market prices to give our customers the ability to optimize their energy consumption and potentially save hundreds of thousands of dollars.
- Sam Vanhoutte, CTO at Codit
We have been part of the private preview for a while and I'm astonished how powerful the platform is. When you're running big queries you can easily assign more processing units and go from 1+ hour of processing to literally 5 minutes.
While sensors are sending us all their events, we are all storing them in Azure Data Lake in their raw format. With Azure Data Lake Analytics we are able to process it and explore what the data is telling us. If the data is no longer relevant, we can aggregate it and archive as long term storage or for deep learning.
I've been interested in big data for a while but managing a cluster scared me and I followed from afar. With Azure Data Lake I'm now capabable to do it myself without having to worry about the clusters I'm running because I don't have to!
Microsoft just made big data easy.
Azure Data Lake Store & Analytics will be in public preview later this year.
Thanks for reading,
Tom.
Thanks to Matt Winkler for reviewing.
Here are the official announcements:
- Announcing General Availability of HDInsight on Linux + new Data Lake Services and Language
- Introducing Azure Data Lake – Microsoft’s expanded vision for making big data easy
- Introducing U-SQL – A Language that makes Big Data Processing Easy
- Microsoft expands Azure Data Lake to unleash big data productivity