Autoscaling Azure Container Instances with Azure Serverless


Azure provides a variety of services to host your workloads on them, all of them with their unique selling points. When choosing your compute infrastructure, you implicitly choose how you will scale them.
Azure Container Instances (ACI) is a great way to run container workloads and positions itself between Azure Functions (FaaS) & Azure Kubernetes Service (Cluster PaaS). However, it does not provide any autoscaling out-of-the-box which can be a show-stopper.
In this blog post, I’ll walk you through the process of building our autoscaler for ACI by using Azure Monitor & Azure Serverless that allows you to scale in/out and publish events to Azure Event Grid for every scaling action to create awareness.
Let’s get started!
Defining Scale Criteria with Azure Monitor
Before we can scale, we need to define the criteria which will trigger either a scale-in or scale-out.
When there is high traffic or a lot of work to process we’ll want to scale out; while if there is nothing to do we’ll want to scale in and optimize our resources for cost & environmental purposes.
This is exactly what Azure Monitor Alerts do - They allow us to define criteria for metrics, and when those criteria are met we want to react to that.
We will create two alerts:
- Scale In Trigger - Defines the criteria for your application to scale in when appropriate, for example "when active message count <= 100"
- Scale-Out Trigger - Defines the criteria for your application to scale out when appropriate, for example "when active message count > 250"
Here’s an overview:
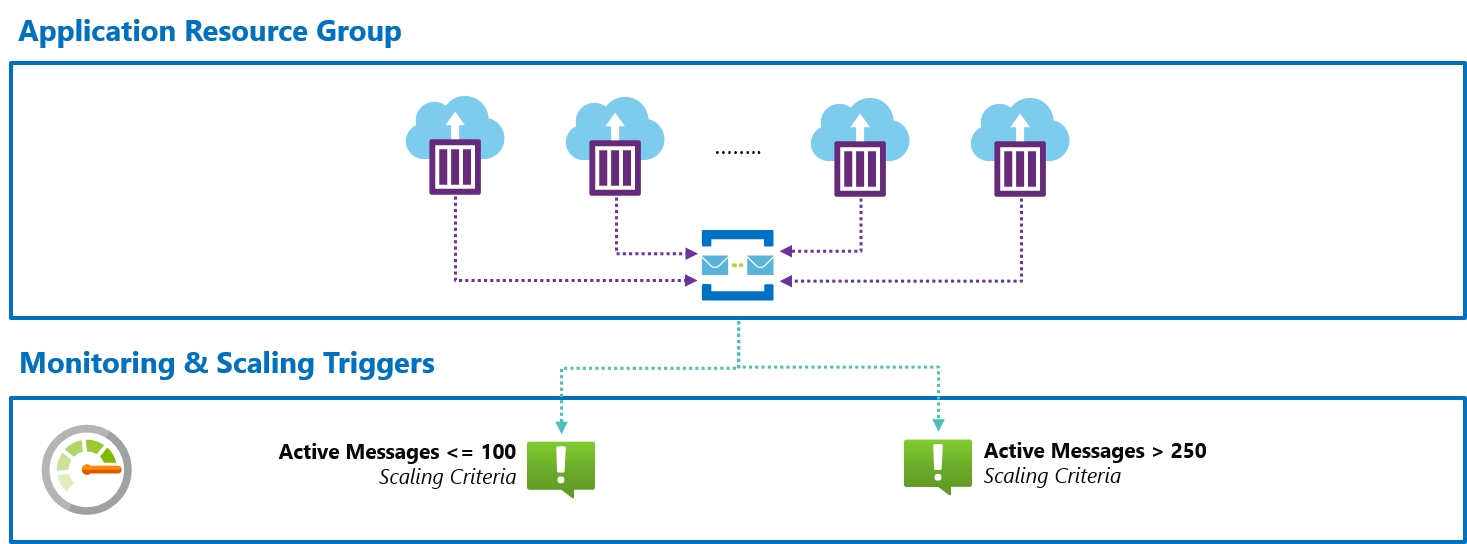
Dead-simple, right? Instead of building this ourselves, we can just use what Azure provides!
There is one caveat, though, to make sure we keep on scaling when the criteria are still met after our scaling cooldown which is the period between two evaluations of the criteria.
By default, Azure Monitor Alerts send a notification to the action group only once, but you can opt-in to get notified every time by using autoMitigate: false.
Making Scaling Decisions with Azure Logic Apps
Now that we know when our scaling criteria are met, we need to make it happen!
Before we start adding/removing instances, we need to make sure that we’re respecting the min/max instance count that was defined.
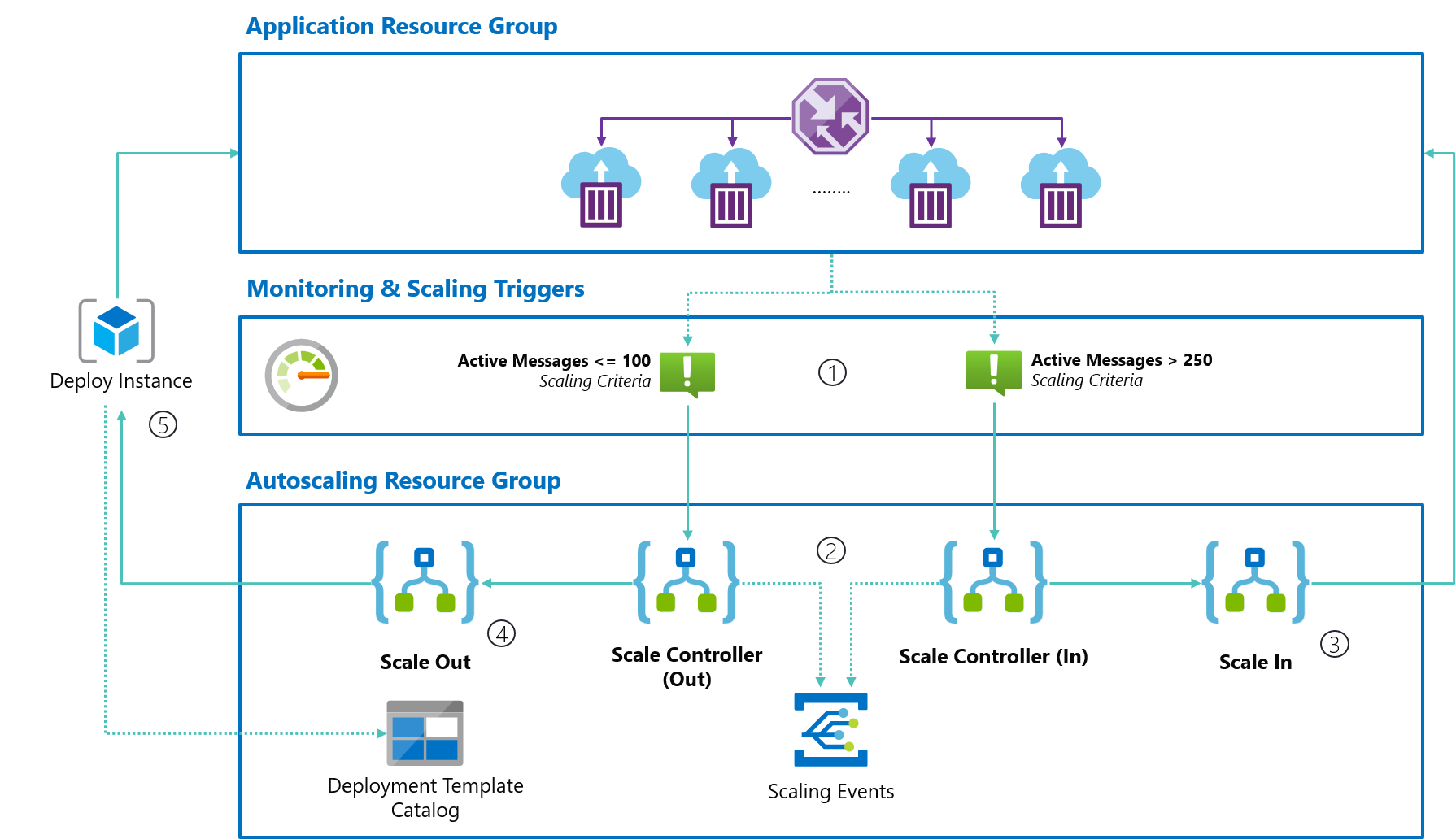
By using Scale Controllers, we can determine if scaling actions need to be taken and trigger a dedicated workflow to do the scaling. This allows the Scale Controller to focus on scaling orchestration & decision making rather than the scaling itself.
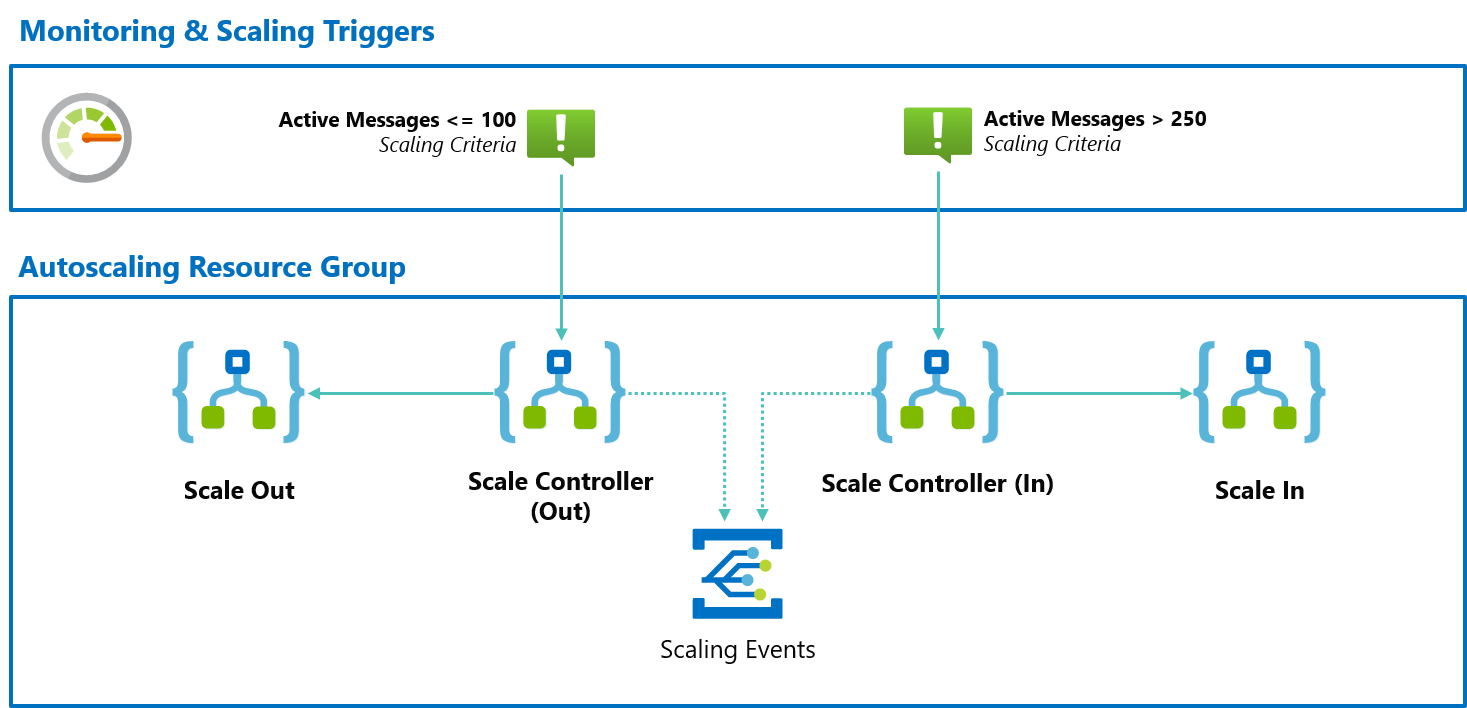
Once the scaling is completed, the Scale Controller will publish an event to Azure Event Grid so that users can subscribe to scaling notifications.
This is essential so that people can plug-in and create scaling awareness by posting in Microsoft Teams, Slack, and/or keep track of all scaling actions and create a scale history.
Using Azure Logic Apps To Scale Application
Time to scale! Scale Controller will trigger the dedicated workflows to make the required actions.
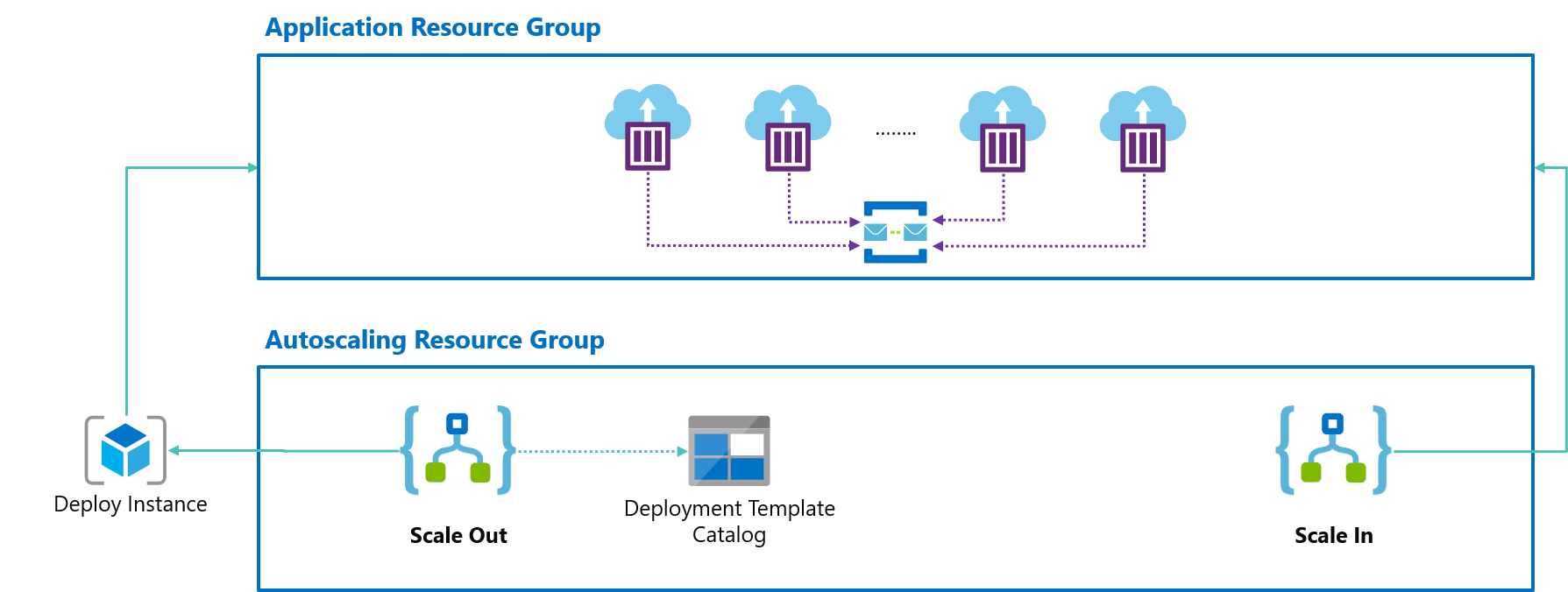
During Scale-Out, we’ll load an ARM template & parameters from our Deployment Template Catalog, replace the instance name placeholder with the real instance name and deploy the ARM template.
During Scale In, we’ll simply use the Azure Container Instance connector to delete a given instance from our pool; that’s it!
Is It Really That Simple? Yes, it really is!
Here’s a visual summary of it:
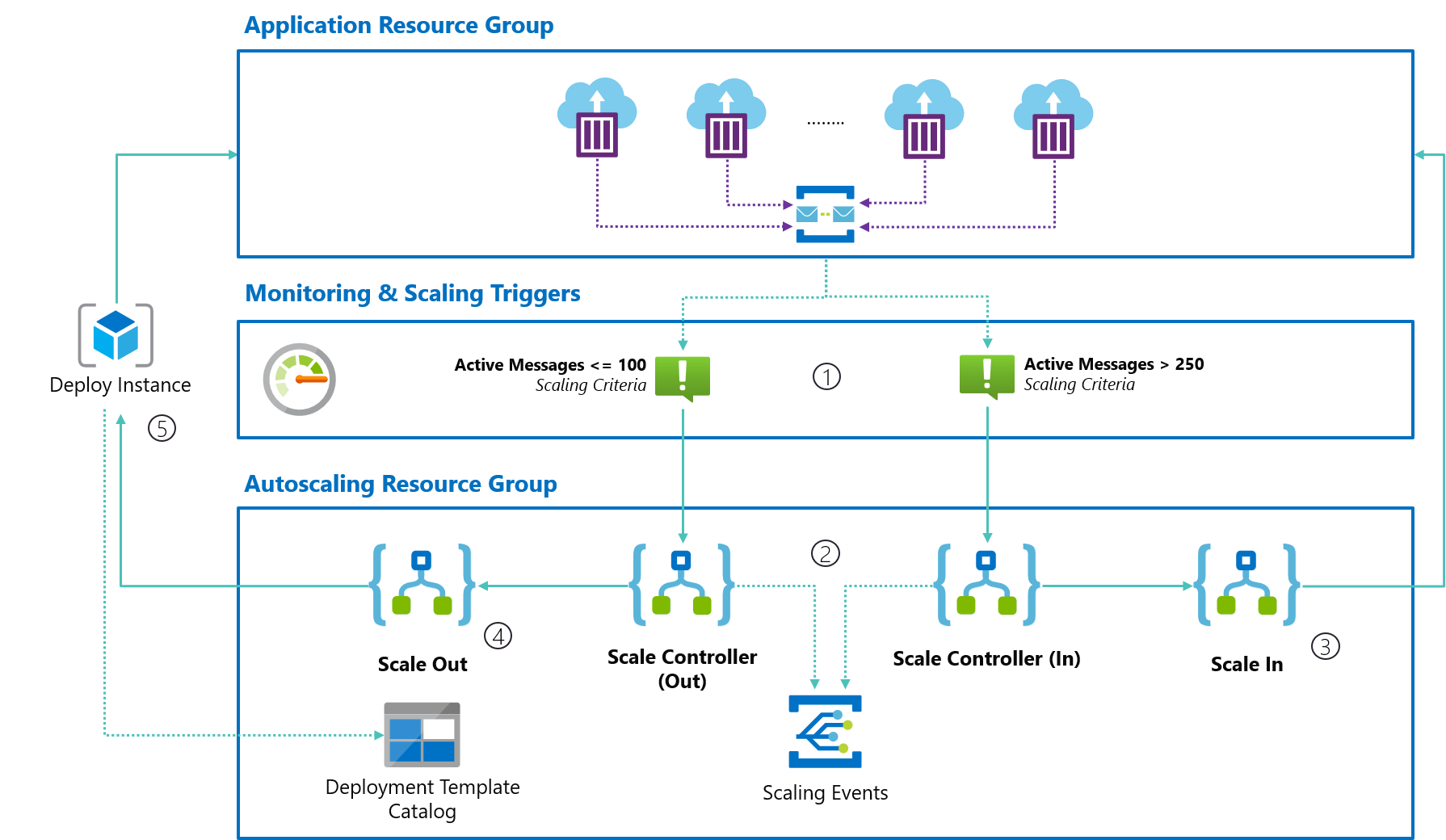
All of it is up and running without writing any line of code nor managing any infrastructure, thanks to Azure Monitor, Azure Logic Apps, and its rich catalog of connectors!
We could have used Azure Functions, but why write any code if you can avoid it? That said, if we would need to make more advanced decisions we could use Azure Functions to extend our solution.
Using HTTP workloads? Azure Traffic Manager to the rescue!
While we have focussed on queue workers, for now, you could use the same approach for scaling your HTTP workloads with the same autoscaler!
The only requirement would be that you introduce Azure Traffic Manager which provides a DNS endpoint for your users to consume and we’ll automatically add/remove instances to the Traffic Manager Profile. (example)
Scaling in, however, would require a small change as we just remove the Azure Container Instance resources and don’t clean-up the Azure Traffic Manager Profile but this could easily be done by removing it through ARM.
Caveats
Now that we have our end-to-end scaling solution, it’s time to talk about the caveats of this POC:
- Our current scaling strategy is linear which is a good starting point, but in some scenarios, you’d rather prefer to add multiple instances per scaling action to more aggressively handle spikes. That said, you could very easily implement this by updating the scaling logic of the Scale Controller(s)
- Currently, all ARM template parameters are stored in Azure Storage and are not being replaced. This means that sensitive parameters, such as secrets, are stored in the Deployment Template Catalog
- While you can scale to 0 instances, it does not ensure that all your queues are empty. This means you’ve potentially scaled to 0 instances, while there are still <100 messages. This can easily be implemented by extending the Scale Controller(s).
- All events to Azure Event Grid are using the Event Grid scheme but I recommend using CloudEvents when possible. Today, Azure Logic Apps does not support it but you can easily send an HTTP request to an Azure Function and use code to send the event yourself.
Keep in mind that this is a POC and not suitable for production. For example, our runtime does not provide alerts while you should have them to make sure you are scaling as it should and not relying on something that is broken.
Conclusion
Azure Container Instances does not provide autoscaling out-of-the-box but this POC shows that you can autoscale it yourself if you build some tooling around it.
It is by far a bullet-proof solution, but it allows us to have a scalable solution until this will be part of the service itself (hopefully).
If you are interested, you can learn more about it on GitHub and deploy it yourself with one of our sample workloads.
Thanks for reading,
Tom.